AI trends 2023

L’année 2023 va connaître une vraie accélération du déploiement de la Data et l’IA.
Trois phénomènes structurants en seront à l’origine :
- Les premières expérimentations à grande échelle en entreprise ont montré l’énorme apport en termes de gains de performance. Ces entreprises, la plupart du temps cotées, vont faire la promotion de ces résultats pour influencer leurs cours de bourse. La main invisible du marché mettra la pression sur l’ensemble de l’industrie.
2. Consommer de la donnée de qualité transversalement dans l’entreprise va devenir une nécessité.
Le Data Management rentre dans une nouvelle phase de maturité tant en termes de prise de conscience que de formalisation avec les grands principes du Data Mesh.
3. La pertinence et la potentielle exploitation industrielle des méga modèles généraux ont été prouvés par la version 3 de ChatGPT. Leur mise sur le marché par les grands acteurs du cloud ouvre de nouveaux horizons et une nouvelle ère d’innovation.
AI Trends 2023, une publication de AI Builders Research, donne les tendances de fond qui vont animer cette année les organisations des grands groupes dans leur volonté d’augmenter leur performance.
1. Une accélération systémique
En se concentrant sur des projets ayant trait à leur coeur de métier, de nombreuses entreprises voient leurs efforts récompensés. La confiance des Directions Générales se renforce et certaines comme La Poste et Philippe Wahl en font leur cheval de bataille. Nous avons assisté en un an à une prise de conscience fulgurante et une généralisation de la transformation Data IA à toutes les entreprises la faisant passer d’optionnelle à impérative.
Fortes de ces premières créations de valeurs, dont il faut avouer que la démonstration est encore une science à elle seule, ces entreprises, la plupart du temps cotées, vont faire la promotion de ces résultats pour influencer leurs cours de bourse. En justifiant leurs investissements auprès des analystes par des résultats probants, ces entreprises vont créer un cercle vertueux dans lequel le marché sanctionnera les entreprises n’ayant pas fait montre d’une optimisation quantitative de leur activité. Il y a fort à parier que les Score Cards des conseils d’administration verront apparaitre un nouvel indicateur non plus de l’avancée de la transformation Data IA dans laquelle on a pu mettre ce que l’on voulait, mais des résultats obtenus.

2. Le Data Mesh conceptualise le Data Management
L’utilisation massive de la donnée ces dernières années a largement démontré son potentiel de création de valeur. La prolifération des projets qui en résulte pousse les organisations à prendre conscience de l’importance de la qualité de la donnée consommée et les incite à mettre en place d’importants programmes de Data Management.
Ces cinq dernières années ont vu les organisations monter en compétences et affiner leurs dispositifs pour répondre au mieux aux besoins de leurs premiers projets. Passer du Data Warehouse au Data Lake, installer une gouvernance, construire des Data Catalog, définir des rôles … Mais tout cela suffit-il à rendre opérationnel le Data Management de toutes les données de l’entreprise, les rôles définis s’impliquent-ils assez, ont-ils la bonne méthode, l’accès à la donnée est-il assez simple dans ce monde hétérogène des systèmes d’information, … et donc pourra-t-on passer à l’échelle ?
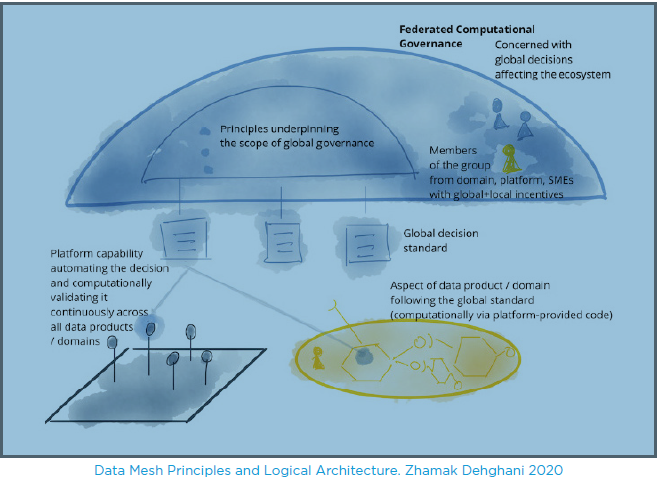
Le 3 Décembre 2020, Zhamak Dehghani, spécialiste des architectures distribuées chez Thoughtworks, publie un article fondateur « Data Mesh Principles and Logical Architecture » dans lequel elle pose les principes qui, selon elle, feront demain une entreprise « Data Driven at Scale ».
Elle donne dans cet article une nouvelle vision logique de l’architecture technique mais surtout organisationnelle de ce que devrait être le Data Management.
Elle propose de structurer sa vision autour de 4 concepts principaux qui forment le Data Mesh :
- Decentralized Domain Ownership
La gestion de la donnée est décentralisée par domaine business au plus près de la source ou du consommateur. Cette vision s’est déjà généralisée dans les organisations les plus matures en termes de Data Management.
- Data as a Product
Certainement le concept le plus fort du Data Mesh mais qui a le plus d’implications :
Il transforme la donnée en un produit presque marchand intégrant tous ses attributs universels au sens du consommateur, de qualité, d’utilisation et de valeur.
Il a pour but de faire passer du rôle passif de l’ETL à des rôles actifs et responsabilisés de Data Developper et Data Product Owner au plus près de la source.
Il relègue la responsabilité et les coûts inhérents du Data Product Ownership au Business Domain générateur de la donnée.
• Self-Serve Data Platform
Ce concept va au-delà du simple accès unique virtualisé à la donnée. Le Self-Serve Data Platform englobe tout le cycle de vie de la donnée et intègre tous les outils et concepts liés à son management. Une vision « intégrée » de la collecte à la consommation plutôt qu’une vision fragmentée par rôles et concepts.
• Federated Computational Governance
Dans cette vision totalement décentralisée du management de la donnée où l’on considère légitime l’autonomie de chaque Domain, il faut cependant se donner les moyens de garder de la cohérence, s’assurer de l’interopérabilité et partager quelques règles communes.
L’application du concept de « fédération », intégrant en même temps les notions d’autonomie et d’intérêt commun, rééquilibre une centralisation nécessaire et une décentralisation naturelle, structurelle et revendiquée. Elle permettra à l’organisation de s’assurer d’une interopérabilité globale des données.

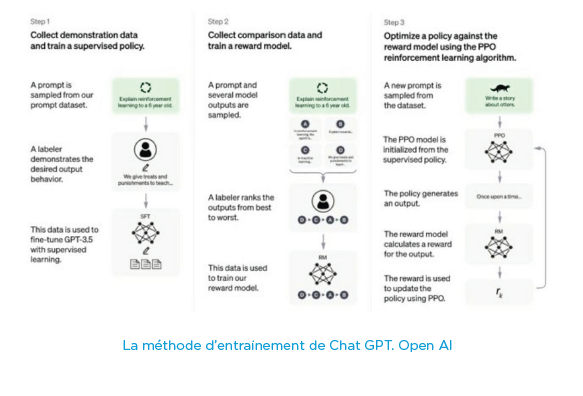
3. GPT-3 : la plateformisation des modèles généraux
L’arrivée sur le marché de Chat GPT-3 d’Open AI marque une vraie révolution qui va reléguer nos bons vieux chatbots et autres moteurs de recherche que nous avions mis des mois voire des années à mettre en oeuvre au rang d’antiquité. Un peu comme si nous passions de la TSF à la Télé 4K en 5 ans. Autant dire que la généralisation de l’utilisation de ce type de modèle dont la proximité du test de Turing contentera largement toute interaction dans le domaine de l’entreprise va une nouvelle fois créer un standard de fait dans l’interaction multimodale comme l’expérience utilisateur, les moteurs de recherche et tout le knowledge management au sens large dans l’entreprise.
Ne nous y trompons pas, les GPT ne sont pas des gadgets mais constituent une vraie rupture. Il y a fort à parier que Google et AWS ne resteront pas en reste après ce coup d’éclat d’Open AI avec ce premier prototype. Il faut plus voir ces GPT comme des plateformes sur lesquelles il sera possible d’entrainer son propre modèle et donc finalement de le contextualiser à son environnement. En effet, Open AI propose dès à présent une API permettant d’utiliser les modèles disponibles en fonction de la rapidité ou de la qualité attendue, de les entrainer avec ses propres données et enfin un pricing à la requête.
Compte tenu de leur taille en milliards de milliards de neurones, du coût exorbitant de leur entrainement et
même du coût de la requête en elle-même, la création de ces plateformes sera limitée à un faible nombre
d’acteurs et nous obligera à l’utilisation de ses plateformes en ligne en mode PaaS.
Les premières utilisations se porteront sur la relation client. Le contraste saisissant dans un contexte post-Covid de généralisation du digital en partie basé sur la qualité de l’expérience client mettra immédiatement une pression énorme sur les vieux chatbots et forcera des pans entiers de la relation multicanale à se précipiter sur ces nouveaux outils. On peut même imaginer de nouvelles formes d’interaction ou de parcours client bien loin du mode « search and basket ». De quoi occuper nos webmarketers et les éloigner du fantasme tridimensionnel du Metaverse.
De la même manière, ces nouveaux outils (surtout dans la version 4 qui sera elle réellement multimodale) ouvrent d’énormes perspectives pour tous les métiers de l’entreprise pour qui il est nécessaire de « produire » à partir d’une base de connaissance ou de documents que l’on pourra maintenant intégrer y compris des règles d’ingénierie. Au-delà de la synthèse de documents jusqu’ici plus que approximative, l’on pourra facilement rechercher, créer des parties d’appel d’offres à la volée, … et trouver de nouveaux assistants qui vont venir encore une fois augmenter la performance des métiers.